AI Agents for CRE Document Analysis: Controls That Matter
Rent rolls, trailing-12s, lease abstracts, and borrower financial packages almost never show up in a consistent format. This article shows how AI tools for CRE document analysis pull key fields, standardize property-level data, flag exceptions for review, and send verified outputs into underwriting models with a clear audit trail.
Commercial real estate lenders still get core underwriting inputs the same old way: emailed PDFs, scanned statements, spreadsheets with broken formulas, and lease files cobbled together from stacks of amendments. AI agents for CRE document analysis are built to turn that mess into structured, reviewable data, with field-level extraction, normalization rules, exception handling, and audit logs an analyst can trace back to the exact page.
This article looks at how those agents work in document-heavy lending workflows, where they break down, and what controls private lenders need before extracted data flows into underwriting models. The focus is on rent rolls, trailing-12 operating statements, borrower financial statements, and lease files, especially the validation logic and reviewer handoffs that make the whole thing usable in practice.
Key Takeaways
- Rent rolls, T-12s, lease abstracts, and borrower statements usually need both extraction and normalization because the same field shows up under different labels, periods, and units depending on the sponsor or property manager.
- Document analysis systems are most dependable when they combine OCR, table detection, rule-based validation, and human exception review instead of trusting one model output.
- The controls that matter most are cross-document reconciliation, field-specific confidence thresholds, and source-linked audit trails that show exactly which page or cell produced each number.
- For private lenders, the real goal is not touchless underwriting. It is faster first-pass analysis, fewer re-keying mistakes, and cleaner handoffs into underwriting and servicing workflows.
- Implementation should start with a narrow document scope, field-level accuracy targets, and explicit exception queues for missing pages, stale statements, and conflicting figures.
What AI agents for CRE document analysis actually do
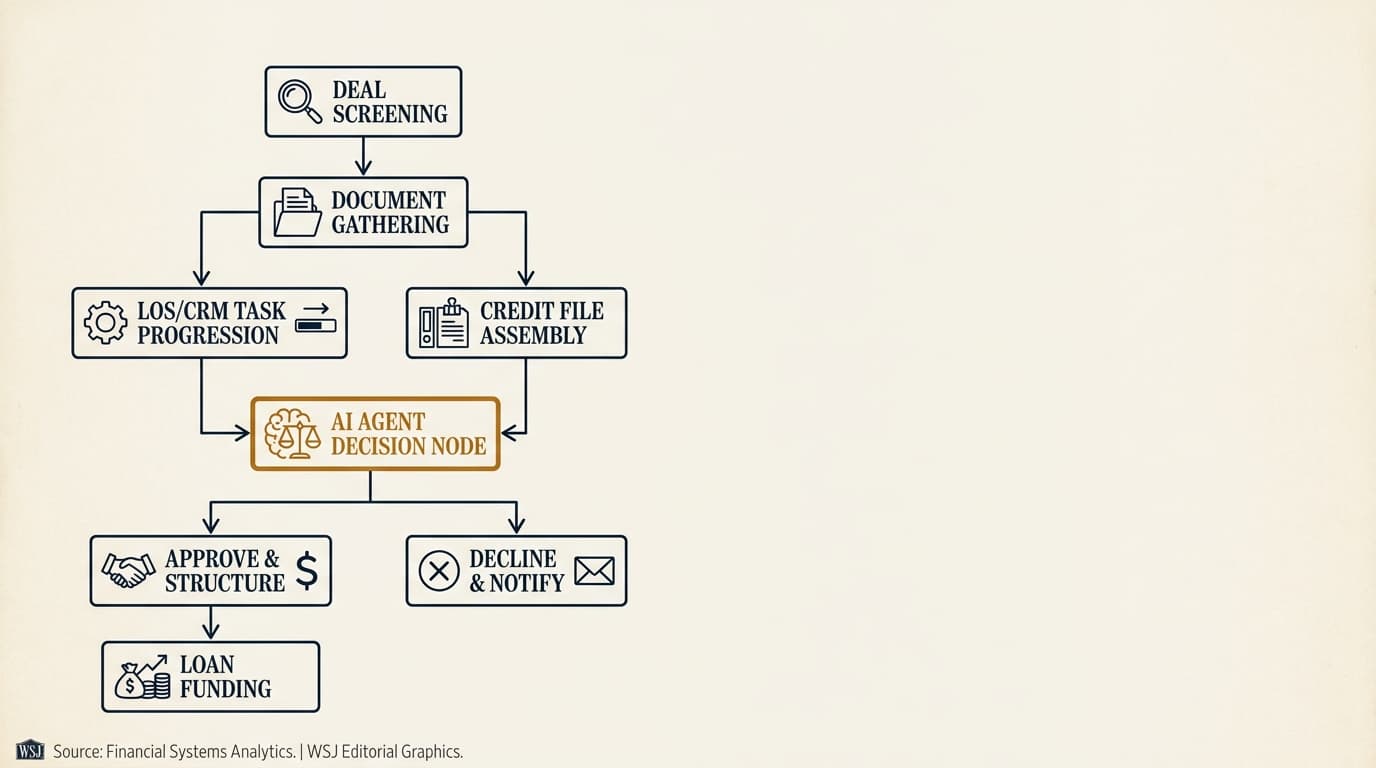
AI agents for CRE document analysis turn unstructured or semi-structured loan file documents into standardized data that underwriting systems can actually use. In practice, that means identifying document type, extracting target fields, mapping inconsistent labels into a common schema, checking outputs against business rules, and routing uncertain items for review.
The components themselves are not new. According to the National Institute of Standards and Technology, machine learning performance depends heavily on test design, data quality, and error measurement. Document analysis works the same way. Good results usually come from a pipeline that combines OCR, layout parsing, table extraction, entity recognition, and deterministic validation rules, not a single generative pass.
In CRE lending, the workflow matters more than the model name. A useful agent should be able to:
- Classify incoming files as rent roll, trailing-12, bank statement, personal financial statement, lease, amendment, or miscellaneous support.
- Extract fields at the right grain, whether that is tenant-level, unit-level, property-level, borrower-level, or guarantor-level.
- Normalize dates, currency formats, rentable square footage, lease terms, and income or expense categories.
- Flag internal inconsistencies, such as a T-12 NOI that does not reconcile to revenue less expenses.
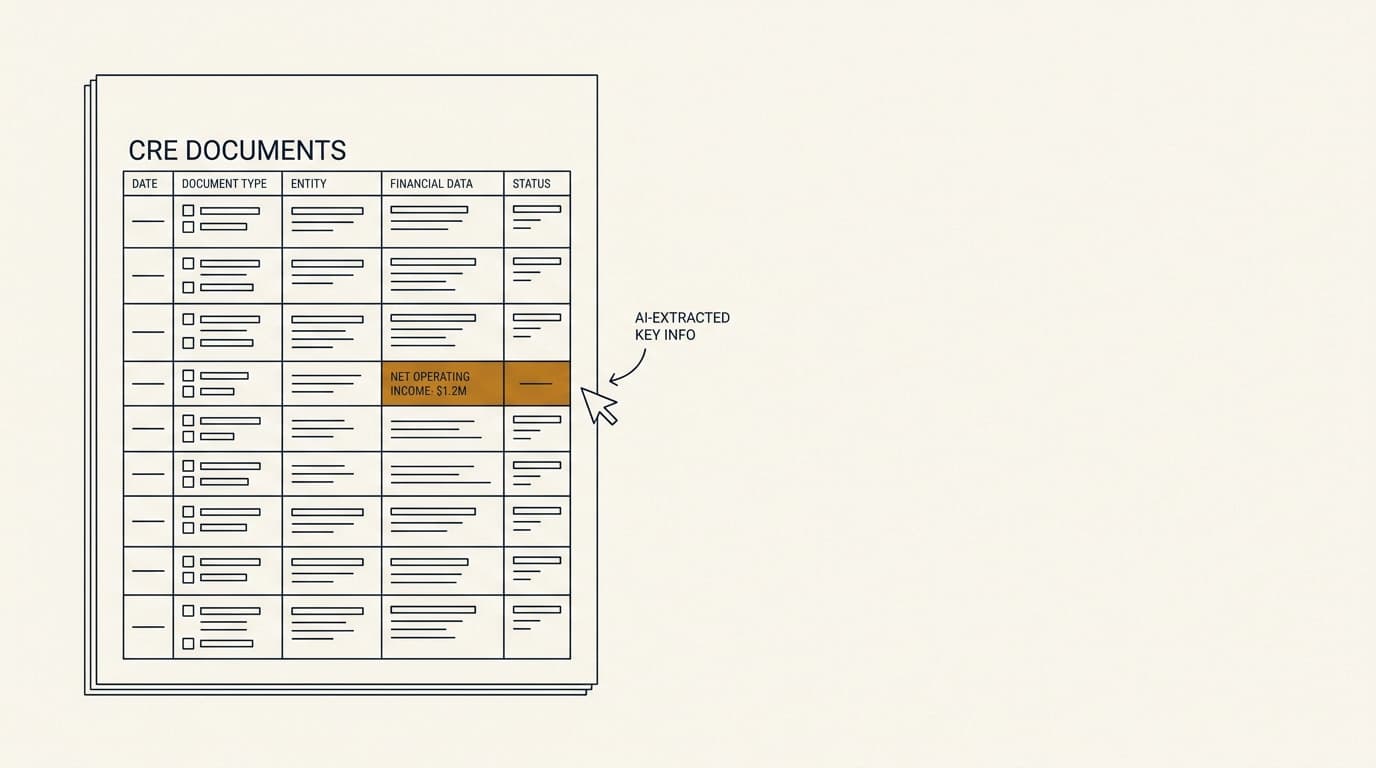
- Attach every extracted value to a source citation, usually a page number, table location, or cell reference.
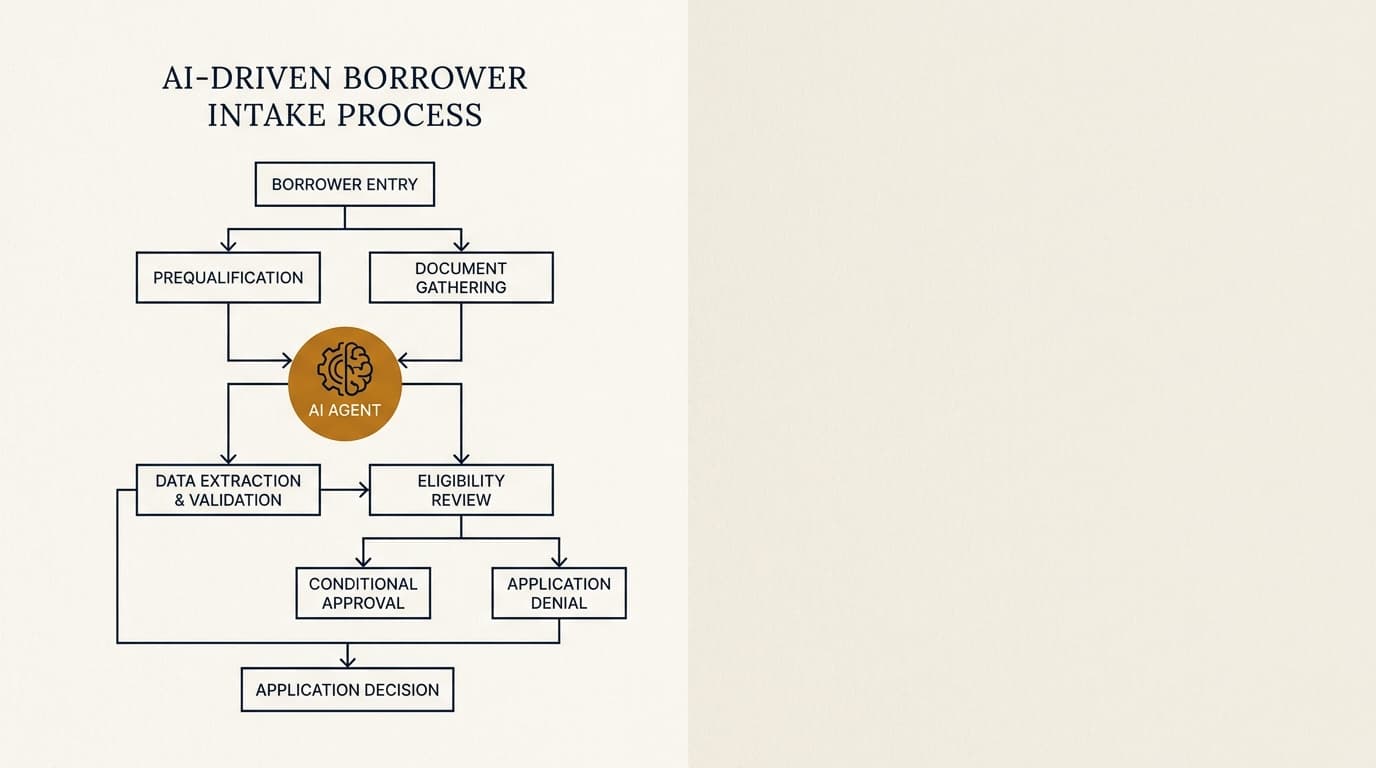
That sits upstream of broader lending workflows. For context on where it fits across the full lifecycle, see ai agents for private commercial real estate lending. This page stays narrower: document intake, extraction, validation, and handoff.
Which CRE documents create the most manual work
In CRE underwriting, most of the manual work comes from a small set of document types that show up again and again. The real time drain is not reading one file. It is reconciling dozens of fields across files prepared by different parties on different dates, usually with different assumptions baked in.
The four document groups below account for most first-pass extraction work in private lending:
| Document type | Typical formats | Main extraction tasks | Common failure points |
|---|---|---|---|
| Rent roll | Excel, PDF export, scanned report | Tenant names, suite/unit, lease dates, rent, reimbursements, occupancy | Merged cells, abbreviations, hidden concessions, inconsistent vacancy labels |
| Trailing-12 operating statement | PDF, Excel, accounting export | Monthly revenue, expenses, NOI, annualized trends | Nonstandard line items, missing months, cash vs accrual differences |
| Borrower financial statements | PDF forms, tax returns, bank statements | Assets, liabilities, liquidity, contingent obligations, recurring income | Multiple account holders, outdated balances, scanned image quality |
| Lease files | Signed PDFs with amendments and exhibits | Base rent schedule, term, options, escalations, expense stops, TI/LC obligations | Amendment conflicts, side letters, missing exhibits, OCR errors in legal text |
According to the Federal Deposit Insurance Corporation guidance on managing risks associated with artificial intelligence, institutions using AI should identify use cases, assess data quality, and apply controls based on the risk of the activity. Document extraction in CRE belongs in the higher-control bucket because those figures feed credit decisions, covenant calculations, and servicing records.
How the extraction and validation workflow works
A solid document analysis workflow follows a simple sequence: ingest, classify, extract, normalize, validate, and escalate. Each stage should leave an auditable record a reviewer can inspect later.
The most reliable operating pattern for private lenders in 2026 is a staged pipeline, not a one-shot parse. A typical implementation looks like this:
- Ingest the uploaded or emailed file and preserve the original version with metadata such as sender, timestamp, and filename.
- Classify the document type and split packets into component files or page ranges if multiple documents were merged.
- Run OCR and layout detection to identify tables, headers, footers, handwriting, stamps, and signatures.
- Extract targeted fields using document-specific prompts or parsers for rent rolls, T-12s, statements, and leases.
- Normalize the extracted data into a standard schema with controlled field names, date formats, and units.
- Apply validation rules, including arithmetic checks, date logic, duplicate detection, and cross-document reconciliation.
- Route low-confidence or conflicting outputs to an exception queue for analyst review.
- Export approved data into the underwriting spreadsheet, loan origination system, or downstream model with a source-linked audit trail.
This workflow often starts before underwriting. If the lender is already automating intake, the document analysis stage should connect to ai agents for borrower intake so the system can catch missing files, stale financials, or unsupported formats before analysts waste time reviewing them.
Why classification errors matter more than OCR errors
Misclassification can cause bigger downstream problems than a bad OCR character. If a current rent roll gets mistaken for an aged receivables report, or a three-month operating statement gets treated as a trailing-12, every calculation after that can be wrong even if the text recognition was technically accurate.
That is why production systems usually treat document type confidence as a gating control. A lender may let a field with 98% confidence pass straight through if it came from a verified rent roll template, while requiring manual review for the same field from an unclassified packet.
Rent roll analysis: fields, failure points, and controls
Rent rolls are usually the highest-volume structured document in CRE underwriting, but they are rarely standardized across sponsors and property managers. A useful extraction agent has to capture both the obvious fields and the context around them.
At minimum, most lenders want the following rent roll fields:
- Tenant name and any doing-business-as variation
- Unit or suite identifier
- Lease start date and expiration date
- Base rent and billing frequency
- Security deposit
- Occupied or vacant status
- Square footage or unit count
- Concessions, abatements, free rent, or discounts
- Recoveries, reimbursements, CAM, taxes, and insurance pass-throughs
- Arrears, delinquency status, or prepaid balances if shown
The hard part is that many rent rolls put current billing, market rent, scheduled rent, and effective rent right next to each other. A model can extract all four correctly and still fail operationally if it maps the wrong one into "current monthly rent." That is one reason lenders evaluating ai document extraction for rent rolls should test mapping accuracy separately from text extraction accuracy.
Rent roll QC checks that catch most errors
Most rent roll extraction errors can be caught with a short set of deterministic checks. They are simple, but they beat broad manual spot reviews because they target failure patterns you actually see in production.
- Total occupied square footage should not exceed total rentable square footage unless the file uses a different denominator.
- Lease expiration dates should not come before commencement dates.
- Vacant units should not carry active tenant names unless the report distinguishes future tenants.
- Monthly rent multiplied by tenant count or unit count should reconcile to subtotal lines within a defined tolerance.
- Column-level totals should tie back to the source report if a total line is present.
One practical control is a side-by-side display of the extracted row and the source image snippet. Reviewers resolve ambiguity much faster when they can see the original line item in context instead of staring at a detached spreadsheet row.
Trailing-12 and borrower financial statement analysis
Trailing-12 statements and borrower financial statements create more ambiguity than rent rolls because the same economic item can be labeled in several ways. The job is less about reading cells and more about classifying financial meaning correctly.
For T-12s, the main objective is to standardize income and expense categories so underwriters can compare properties prepared on different accounting systems. One property manager may separate payroll taxes, contract labor, and onsite payroll. Another may bury all labor in one line. The normalization layer has to preserve source detail while mapping each line into a reusable chart of accounts.
According to the Financial Accounting Standards Board Accounting Standards Codification, financial reporting presentation can vary based on entity and reporting basis, which helps explain why raw statements are hard to compare across borrowers. In lending practice, document analysis tools usually apply a lender-defined taxonomy for categories such as rental income, other income, repairs and maintenance, utilities, administrative, taxes, insurance, and capital items excluded from NOI.
T-12 reconciliation rules that matter in underwriting
The best validation rules for T-12 data focus on underwriting relevance, not bookkeeping purity. The point is to catch figures that would distort NOI, DSCR, or implied value.
| Validation rule | Why it matters | Typical exception |
|---|---|---|
| Total revenue less total operating expenses equals NOI | Prevents broken formulas from flowing into credit sizing | Owner includes below-the-line items in operating expenses |
| Statement period covers 12 months | Short periods distort annualized assumptions | Year-to-date statement submitted instead of trailing-12 |
| Property taxes and insurance compared to prior year or borrower narrative | Catches missing accruals or one-time adjustments | Recent reassessment or carrier change |
| Large month-over-month swings flagged above threshold | Identifies seasonality, deferred maintenance, or posting errors | Annual true-ups, snow removal, turnover costs |
Borrower statements add another layer because identity resolution becomes part of extraction. The system has to determine whether an account belongs to the borrower, guarantor, affiliated entity, or an unrelated joint holder. It also needs to distinguish liquid assets from restricted cash, retirement accounts, pledged collateral, and accounts that are stale under lender policy.
Those outputs feed downstream risk assessment. The fuller discussion belongs on ai agents for cre underwriting, but the document analysis layer decides whether those later calculations start with clean data or garbage.
Lease file analysis and abstract generation
Lease abstraction is where document analysis stops being a table extraction problem and starts becoming a contract interpretation problem. The task is not just finding text. It is figuring out which clause actually controls after amendments, renewals, exhibits, and side letters are taken into account.
Lease files often include a signed lease, one or more amendments, guaranties, commencement letters, estoppels, and exhibits with rent schedules or site plans. A workable agent should build a chronology first, then abstract only the active commercial terms after applying later amendments over earlier language.
Fields private lenders usually need from lease files
Private lenders usually do not need a full legal abstract for every tenant. They need the terms that affect cash flow durability, rollover risk, and landlord obligations.
- Original term and current expiration
- Base rent schedule and escalation structure
- Renewal, termination, contraction, or expansion options
- Expense reimbursement structure such as gross, modified gross, or triple net
- Tenant improvement, leasing commission, or free-rent obligations still outstanding
- Go-dark rights, co-tenancy clauses, exclusives, and assignment/subletting provisions where material
- Security deposits, letters of credit, or guaranties
According to the Consumer Financial Protection Bureau's compliance resources, institutions should be able to explain how automated systems affect decisions and keep records that support review. Commercial lending is not governed by the same consumer mortgage rules in every respect, but the operational lesson still applies: if an extracted lease term affects underwriting, the system should preserve the source clause and amendment trail.
The edge case that standard software often misses is a partial amendment override. For example, Amendment No. 3 may revise only the rent commencement date while leaving the original escalation schedule alone. A reliable system has to preserve both truths at the same time instead of overwriting the entire clause set.
Accuracy controls: confidence scoring, reconciliation, and exception queues
Document analysis in lending should be treated like a data production process, not a generic productivity tool. The standard is not whether the model sounds plausible. The standard is whether each material field is traceable, tested, and reviewable.
Three control layers matter most:
1. Field-level confidence thresholds
Confidence should be measured by field and document class, not at one file level. Dates, tenant names, and currency amounts fail in different ways, so their pass thresholds should differ. A lender may auto-accept a tenant name above a defined confidence level while requiring review for lease expiration dates because date errors directly affect rollover analysis.
2. Cross-document reconciliation
The strongest control is comparison across independent sources. If annualized base rent from the rent roll differs materially from the lease abstract or from borrower-reported property revenue, the file should go to exception review. Cross-document checks catch mistakes no single-document parser can see.
3. Human exception review with reason codes
Exception queues only work if reviewers classify what went wrong. Reason codes such as "missing pages," "unreadable scan," "conflicting amendment," "period mismatch," and "nonstandard line item" let the lender measure recurring failure modes and improve templates or borrower instructions.
According to the International Organization for Standardization's ISO/IEC 23894 guidance on AI risk management, organizations should identify, analyze, evaluate, and treat AI-related risks throughout the lifecycle. In CRE document analysis, that means version control, exception logs, sampling protocols, and escalation paths for material discrepancies.
How document analysis outputs connect to underwriting models
Document analysis only creates operational value when validated outputs move cleanly into the lender's existing model environment. The handoff needs enough structure for spreadsheets and rules engines, but enough constraint to prevent silent field drift.
In practice, the best integration design uses a canonical schema with stable field definitions. For example, "in_place_base_rent_annual" should mean exactly one thing across all property types and source systems. That lets the underwriting model ingest standardized data while still linking back to page-level evidence.
This handoff matters even more when the lender uses downstream automation in ai agents for cre loan origination or post-close workflows in ai agents for loan servicing. If the extracted data model changes every quarter, origination and servicing teams end up rebuilding mappings instead of using the system.
What good handoffs look like in practice
A clean handoff into underwriting models generally includes:
- Structured JSON or tabular export with stable field names
- Document and page references for each material value
- Flags for reviewer-approved overrides
- Period labels and as-of dates preserved from source documents
- Difference reports showing what changed between file versions
The difference report does not get enough attention. In repeated borrower submissions, the lender needs to know whether the new rent roll changed occupancy, whether a T-12 update changed NOI in a meaningful way, and whether a revised lease file changed rollover assumptions. That delta view is usually more useful than reprocessing the whole package as if nothing came before it.
A decision framework for private lenders evaluating document analysis agents
The right evaluation framework is not "Which vendor claims the highest accuracy?" It is "Which workflow gives us acceptable error rates, explainability, and review effort for our actual document mix?"
Private lenders can break the evaluation into three scenarios:
| Scenario | Best fit | Main benefit | Main risk |
|---|---|---|---|
| High-volume bridge or small-balance lending with repeated document types | More automation, stricter templates | Faster first-pass extraction and lower analyst re-keying time | Template drift if brokers submit off-format files |
| Mid-market relationship lending with mixed property types | Hybrid workflow with broad exception review | Better consistency across analysts and files | Overconfidence in partially normalized outputs |
| Large bespoke transactions with dense lease packages and complex structures | Targeted extraction plus analyst-led abstraction | Audit trail and faster issue spotting | Limited full automation because legal and structural edge cases dominate |
The deeper point is that document analysis should be judged on error containment, not just labor savings. A system that extracts 85% of fields automatically but reliably isolates the uncertain 15% may be stronger operationally than one that tries to push 99% straight through without clear exception logic.
This is also where lenders should test the edge cases vendor demos tend to avoid: stacked amendments, hand-marked scans, portfolio packages with multiple entities, rent rolls exported as images, and T-12s with borrower-specific line items that do not fit a standard chart.
Implementation checklist: how to roll out AI agents for CRE document analysis safely in 2026
A safe rollout starts narrow, measures field-level performance, and expands document coverage only after the exceptions are understood. The quickest way to disappoint yourself is to attempt full-file automation across every property type on day one.
- Define the first document scope, such as rent rolls and trailing-12 statements for multifamily and office loans only.
- Specify the exact target fields, accepted formats, and normalization rules before any model tuning begins.
- Assemble a test set with clean files, poor scans, amendments, and intentionally messy edge cases.
- Measure extraction accuracy at the field level and separately measure mapping accuracy into the lender's schema.
- Set confidence thresholds and exception rules for each material field, not just each file.
- Require page-level source citations and preserve the original file for every extracted output.
- Pilot the workflow with a limited analyst group and compare time saved, override rates, and error categories against the manual baseline.
- Integrate only reviewer-approved outputs into underwriting models and monitor drift as document formats change.
For private lenders, that sequence usually works better than chasing a fully autonomous system. The target is measurable: shorter analysis time without giving up control quality.
Frequently Asked Questions
What is an AI agent for CRE document analysis?
An AI agent for CRE document analysis is software that classifies loan file documents, extracts targeted fields, normalizes them into a lender-defined schema, applies validation rules, and routes uncertain outputs for review. In commercial real estate lending, the usual source documents are rent rolls, trailing-12 operating statements, lease files, and borrower financial statements.
How accurate are AI agents for rent rolls and T-12 statements?
Accuracy depends on document quality, file format consistency, and the control design around the model. Clean spreadsheet exports usually perform better than scanned PDFs, and field-level accuracy tells you more than a single file-level score. In production, lenders should test extraction accuracy, mapping accuracy, and reconciliation pass rates separately.
What controls should private lenders require before using extracted document data in underwriting?
At minimum, lenders should require source-linked audit trails, field-level confidence thresholds, arithmetic and date validation, cross-document reconciliation, and a documented exception review queue. Files with missing pages, conflicting figures, or unsupported formats should be blocked from direct model ingestion until a reviewer clears them.
Does document analysis replace underwriting analysts?
No. In most CRE lending teams, document analysis reduces manual re-keying and speeds up first-pass review, but analysts still resolve exceptions, interpret lease terms, assess sponsor explanations, and decide how normalized figures should be used in credit analysis. In practice, the work shifts away from transcription and toward review and judgment.
Do results vary by market or property type?
Yes. Multifamily and standard office rent rolls are often easier to normalize than hospitality reports, retail lease packages with co-tenancy language, or mixed-use portfolios spread across multiple states. Regional variation matters too, especially where lease forms, property management systems, and tax or reimbursement practices differ. Lenders should test by property type and geography instead of assuming one accuracy rate applies across the whole pipeline.